
SEO optimalizácia nám vie bez pochyby pomôcť dostať sa na vyššie pozície vo vyhľadávačoch a je len na nás, či sa rozhodneme jednotlivé postupy týkajúce sa SEO využiť alebo nie. V dnešnom článku sa pozrieme na pokročilé SEO a hlbšie na význam robots.txt.
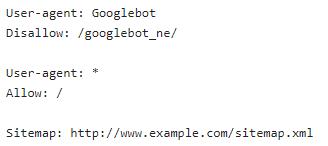 V prvom riadku user-agent máte možnosť vyčleniť určitého bota a v druhom riadku mu s príkazom Disallow zakázať prístup do konkrétneho priečinku (automaticky aj do podpriečinkov).
Príkaz User-agent: * znamená, oslovenie všetkých ostatných botov resp. užívateľských agentov. V riadku pod ním vidíme Allow: / čo znamená, že web majú povolený prístup všade. Rovnaký efekt by to malo aj v prípade ak by sme do druhého riadku napísali Disallow: (za dvojbodkou by sme nenapísali nič). Alebo druhá možnosť ak by sme vynechali celý príkaz User-agent: * a Allow: / (v našom prípade 3. a 4. riadok) malo by to rovnaký vplyv ako keby tam príkaz bol. Pretože boty majú prístup automaticky všade bez toho aby ste im povolili.
Nemenej dôležitý je posledný riadok, ktorý poskytuje informáciu o tom, kde sa nachádza site Váš sitemap. Týmto riadkom poskytnete podstatné informácie pre lepšie pochopenie Vášho webu, čo pomôže nie len vyhľadávačom ale hlavne Vám.
Súbor robots.txt si viete vytvoriť alebo upraviť aj vy sami napríklad prostredníctvom FTP prístupu.
Len pre zaujímavosť. Google má aktuálne 12 takzvaných „crawlerov“, ktorý skenujú naše webstránky. Najhlavnejší zo všetkých je Googlebot, ktorý sme si uviedli v príklade aj my.
V ďalšom článku si bližšie posvietime na XML Sitemap, aký má význam a tiež, čo a prečo by mal obsahovať.
V prvom riadku user-agent máte možnosť vyčleniť určitého bota a v druhom riadku mu s príkazom Disallow zakázať prístup do konkrétneho priečinku (automaticky aj do podpriečinkov).
Príkaz User-agent: * znamená, oslovenie všetkých ostatných botov resp. užívateľských agentov. V riadku pod ním vidíme Allow: / čo znamená, že web majú povolený prístup všade. Rovnaký efekt by to malo aj v prípade ak by sme do druhého riadku napísali Disallow: (za dvojbodkou by sme nenapísali nič). Alebo druhá možnosť ak by sme vynechali celý príkaz User-agent: * a Allow: / (v našom prípade 3. a 4. riadok) malo by to rovnaký vplyv ako keby tam príkaz bol. Pretože boty majú prístup automaticky všade bez toho aby ste im povolili.
Nemenej dôležitý je posledný riadok, ktorý poskytuje informáciu o tom, kde sa nachádza site Váš sitemap. Týmto riadkom poskytnete podstatné informácie pre lepšie pochopenie Vášho webu, čo pomôže nie len vyhľadávačom ale hlavne Vám.
Súbor robots.txt si viete vytvoriť alebo upraviť aj vy sami napríklad prostredníctvom FTP prístupu.
Len pre zaujímavosť. Google má aktuálne 12 takzvaných „crawlerov“, ktorý skenujú naše webstránky. Najhlavnejší zo všetkých je Googlebot, ktorý sme si uviedli v príklade aj my.
V ďalšom článku si bližšie posvietime na XML Sitemap, aký má význam a tiež, čo a prečo by mal obsahovať.
Čo je to robots.txt a aký je jeho význam?
Naším poslaním je čo najefektívnejšie optimalizovať web pre jazyk vyhľadávačov aby ho pochopili a pod vplyvom viacerých faktorov umiestnili na čo najvyššie pozície. Súbor robots.txt by mal byť súčasťou každého webu. Súbor poskytuje rôznym robotom, ktoré prechádzajú Váš web, informácie o tom, ku ktorým priečinkom na webe nemajú prístup. Je to zároveň jeden z prvých súborov na, ktoré sa vyhľadávače pri indexácií pozerajú. Je na Vás, či im zamedzíte prístup do všetkých priečinkov, do určitého priečinku alebo im nezamedzíte prístup vôbec. Ak si otvoríte robots.txt textový súbor s veľkou pravdepodobnosťou v ňom budete vidieť niektorý z týchto pravidiel.
V prvom riadku user-agent máte možnosť vyčleniť určitého bota a v druhom riadku mu s príkazom Disallow zakázať prístup do konkrétneho priečinku (automaticky aj do podpriečinkov).
Príkaz User-agent: * znamená, oslovenie všetkých ostatných botov resp. užívateľských agentov. V riadku pod ním vidíme Allow: / čo znamená, že web majú povolený prístup všade. Rovnaký efekt by to malo aj v prípade ak by sme do druhého riadku napísali Disallow: (za dvojbodkou by sme nenapísali nič). Alebo druhá možnosť ak by sme vynechali celý príkaz User-agent: * a Allow: / (v našom prípade 3. a 4. riadok) malo by to rovnaký vplyv ako keby tam príkaz bol. Pretože boty majú prístup automaticky všade bez toho aby ste im povolili.
Nemenej dôležitý je posledný riadok, ktorý poskytuje informáciu o tom, kde sa nachádza site Váš sitemap. Týmto riadkom poskytnete podstatné informácie pre lepšie pochopenie Vášho webu, čo pomôže nie len vyhľadávačom ale hlavne Vám.
Súbor robots.txt si viete vytvoriť alebo upraviť aj vy sami napríklad prostredníctvom FTP prístupu.
Len pre zaujímavosť. Google má aktuálne 12 takzvaných „crawlerov“, ktorý skenujú naše webstránky. Najhlavnejší zo všetkých je Googlebot, ktorý sme si uviedli v príklade aj my.
V ďalšom článku si bližšie posvietime na XML Sitemap, aký má význam a tiež, čo a prečo by mal obsahovať. 

 Spotify
Spotify  Apple podcasts
Apple podcasts  Youtube
Youtube